If you work in a diligent web development business you probably know what an A/B test is. However, its fascinating statistical theory is usually left behind. Understanding the basics can help you avoid common pitfalls, better design your experiments, and ultimately do a better job in improving the effectiveness of your website.
Please hold tight, and enjoy a pleasant statistical journey with the help of R and some maths. You will not be disappointed.
This blog post is also published on my company blog which inspired those studies.
Introduction
An A/B test is a randomized, controlled experiment in which the performance of two product variants are compared. Those variants are usually called A and B 1. From a business perspective we want to know if the performance of a certain variant outperforms the other.
As an example let’s take a typical checkout page where we want to assess if a green checkout button is more effective than an orange one.
After 1 week we may collect the following numbers:
| Converted | Total | |
|---|---|---|
| Variant A | 100 | 10000 |
| Variant B | 120 | 10000 |
If at this point you are willing to conclude that the B variant outperforms A be aware you are taking a very naïve approach. Results can vary on a weekly basis because of the intrinsic randomness of the experiment. Put simply, you may be plain wrong. A more thorough approach would be to estimate the likelihood of B being better than A given the number we measured, and statistics is the best tool around for this kind of job.
Statistical modeling
Statisticians love jars and, guess what, our problem can be modeled as an extraction from two different jars. Both jars have a certain ratio of red and green balls. Red balls are customers who end up paying while green balls are customers who leave.
Does the jar belonging to variant B have a greater proportion of red balls compared to the other one? We can estimate this ratio by doing an extraction with replacement 2 from the jar. We extract a finite number of balls from each jar and we measure the proportions. In this type of experiment each time we pick a ball we also put it back to the jar to keep the proportions intact.

Now the good news is that the Binomial distribution 3 models exactly this type of experiment. It will tell you the expected number of successes in a sequence of $n$ independent yes/no experiments, each of which yields success with probability $p$.
In other words, each time we extract $n$ balls from our jar we are conducting an experiment, and a yes corresponds to a red ball while a no corresponds to a green ball. The binomial distribution 4 computes the probability of picking exactly $k$ red balls after $n$ extractions as follows:
(a) $Pr(X = k) = \frac{n!}{k!(n-k)!} p^k (1-p)^{n-k}$
which can be checked using the dbinom() function in R. Assuming we have a jar with 30% of red balls, what is the probability that we extract exactly 10 red balls out of a 100? This is equivalent to $Pr(X = 10)$ which is:
|
1 2 |
dbinom(10, 100, 0.3) # => 1.17041796785404e-06 |
Very small. Fair enough, the jar has definitely a bigger proportions of red and I was the unlucky guy here. Now, let’s plot these values for x (number of successes) ranging between 0 and 100:
|
1 2 3 4 5 |
x = 1:100 y = dbinom(x, 100, 0.3) options(repr.plot.width=7, repr.plot.height=3) qplot(x, y, xlab="Number of successes", ylab="Probability") + xlim(0, 60) |
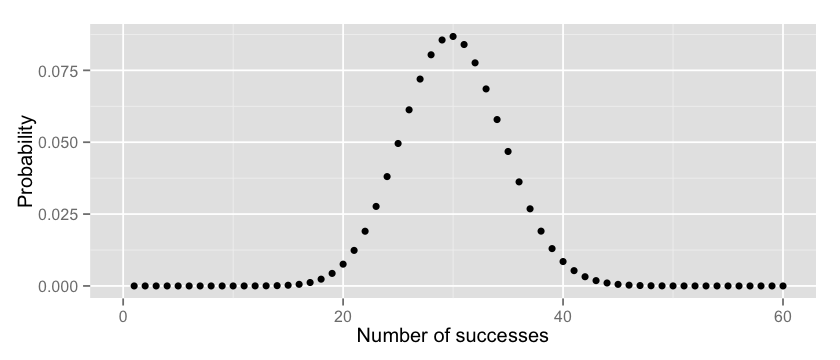
Makes sense, doesn’t it? The chances of having exactly k successes cumulates around the value of 30, which is the true proportion of red/green balls in our jar.
Naïve experiment assessment
Now that we know how statisticians model our problem let’s go back to our conversions table.
One way of assessing if B is better than A is to plot their expected distributions. Assuming that A follows a Binomial distribution with $p=0.01$ (we had 100 conversions over 10000 trials) and that B follows a Binomial distribution with $p=0.012$ (we had 120 conversions over 10000 trials) this is how they relate to each other:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
x_a = 1:10000 y_a = dbinom(x_a, 10000, 0.01) x_b = 1:10000 y_b = dbinom(x_b, 10000, 0.012) data = data.frame(x_a=x_a, y_a=y_a, x_b=x_b, y_b=y_b) options(repr.plot.width=7, repr.plot.height=3) cols = c("A"="green","B"="orange") ggplot(data = data)+ labs(x="Number of successes", y="Probability") + xlim(0, 200) + geom_point(aes(x=x_a, y=y_a, colour="A")) + geom_point(aes(x=x_b, y=y_b, colour="B")) + scale_colour_manual(name="Variants", values=cols) |
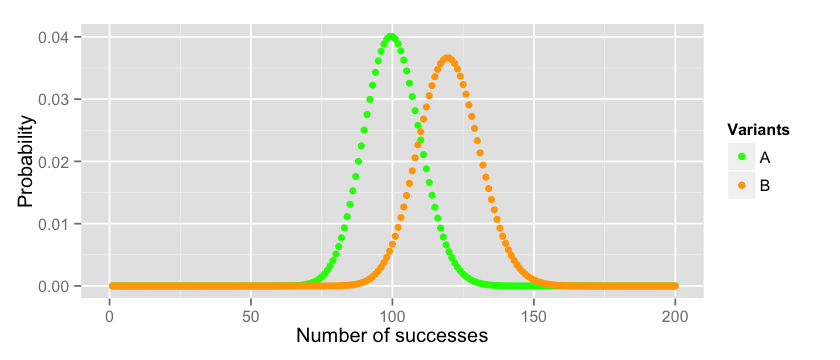
So if the true mean of the two distribution is $p_a = 0.01$ and $p_b = 0.012$ respectively we can conclude that B is better than A. If we repeat the experiment several times (always with 10000 participants) for A we will get most of the time values between $70$ and $129$ while for B we will get values between $87$ and $152$. You can check these boundaries on the plot, or you can compute them manually with the 3 times standard deviation rule of thumb 5.
|
1 2 3 4 5 |
n=10000; p=0.01; q=1-p; mean=100 paste(mean - 3 * sqrt(n*p*q), "," ,mean + 3 * sqrt(n*p*q)) n=10000; p=0.012; q=1-p; mean=120 paste(mean - 3 * sqrt(n*p*q), ",", mean + 3 * sqrt(n*p*q)) |
But hold on one minute. How do we know that $p_a = 0.01$ and $p_b = 0.012$ are indeed the true means of our distributions? In the end we simply did one extraction from our jars. If these numbers are wrong our distributions will look different and the previous analysis will be flawed. Can we do better?
More rigorous experiment assessment
In order to estimate what is the true mean of our variants statisticians rely on the Central Limit Theorem (CLT) 6 which states that the distribution of the mean of a large number of independent, identically distributed variables will be approximately normal, regardless of the underlying distribution.
In our case we are trying to estimate the distribution of the mean of the proportions $p_a$ and $p_b$ for our variants. Suppose you run your A/B test experiment $N=100$ times and that each time you collect $n=10000$ samples you will end up having for variant A:
$p_a^1, p_a^2 … p_a^N$
and the CLT tells us that these are normally distributed with parameters:
$\mu_p = p$, $\sigma_p = \frac{\sigma}{sqrt(n)} * \frac{N-n}{N-1} \approx \sqrt{\frac{p * (1-p)}{n}}$
where $\sigma = \sqrt{p * (1-p)}$ is the standard deviation of the binomial distribution. I know, this is hard to believe and proving these numbers goes definitely beyond the scope of this blog post so you will find some maths-heavy material in the footnotes 7 8.
Back to our question, what is the true mean of $p_a$ and $p_b$? Well, we don’t know really, but they are distributed normally like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
x_a = seq(from=0.005, to=0.02, by=0.00001) y_a = dnorm(x_a, mean = 0.01, sd = sqrt((0.01 * 0.99)/10000)) x_b = seq(from=0.005, to=0.02, by=0.00001) y_b = dnorm(x_b, mean = 0.012, sd = sqrt((0.012 * 0.988)/10000)) data = data.frame(x_a=x_a, y_a=y_a, x_b=x_b, y_b=y_b) options(repr.plot.width=7, repr.plot.height=3) cols = c("A"="green","B"="orange") ggplot(data = data)+ labs(x="Proportions value", y="Probability Density Function") + geom_point(aes(x=x_a, y=y_a, colour="A")) + geom_point(aes(x=x_b, y=y_b, colour="B")) + scale_colour_manual(name="Variants", values=cols) |
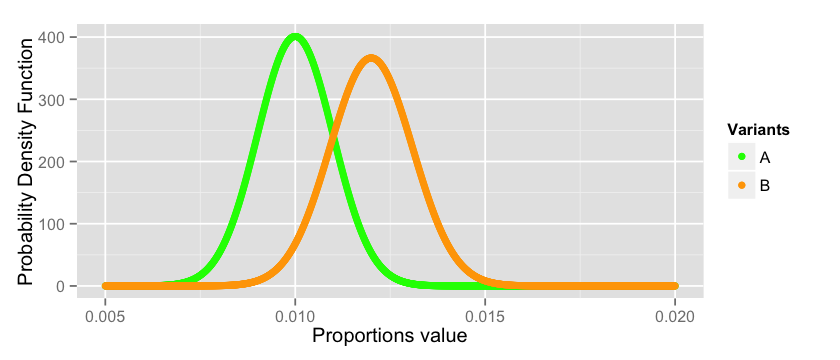
As you can see we are dealing with a risky business here. There is a good chance that the estimation of the true values of $p_a$ and $p_b$ are not correct since they can span anywhere between all the values plotted above. For a good number of them $p_a$ may actually outperform $p_b$ violating the conclusion we did in the previous section. There is no magic bullet that will solve this problem, this is the intrinsic nature of the probabilistic world in which we live. However, we can do our best to quantify the risk and take a conscious decision.
Quantitative evaluation
In the previous section we have seen that it is likely that Variant B is better than Variant A, but how can we quantify this statement? There are different ways in which we can look at this problem, but the ones that statisticians use is Hypothesis testing.
In a series of papers in the early 20th century, J. Neyman and E. S. Pearson developed a decision-theoretic approach to hypothesis-testing 9. The theory was later extended and generalised by Wald 10. For a full account of the theory, see the book of Lehmann and Romano 11.
In this framework we state a hypothesis (also called null-hypothesis) and by looking at the number we will try to reject it. In our example we hypothesize that the true conversion of our visitors is $p_a$ and that the proportion $p_b$ we collected in the B variant is simply due to chance. In other words we assume that our real world visitors behave like in variant A and we quantify the probability of seeing variant B’s proportions under this hypothesis.
So, what is the probability of having $120$ or more conversions if the true mean of the binomial distribution is $p_a = 0.01$? We simply have to sum the probability of all possible events:
$$P(X_a >= 120) = P(X_a=120) +P(X_a=121) + … + P(X_a = 10000)$$
To actually compute the number you can use the probability mass function in Formula (a) or you can use R:
|
1 |
binom.test(120, 10000, p = 0.01, alternative = "greater") |
which gives us the following:
|
1 2 3 4 5 6 7 8 9 10 |
Exact binomial test data: 120 and 10000 number of successes = 120, number of trials = 10000, p-value = 0.0276 alternative hypothesis: true probability of success is greater than 0.01 95 percent confidence interval: 0.01026523 1.00000000 sample estimates: probability of success 0.012 |
I deliberately specified alternative = "greater" in the function call to compute the chance of getting more than 120. But there are other ways 12 to approach the problem. The value we are looking for is the p-value 13 0.0276 which is exactly the probability of getting more than 120 successes, i.e. $P(X_a >= 120)$. Visually it corresponds to the area under the right end tail of the distribution of A:
|
1 2 3 4 5 6 7 8 9 |
x_a = 1:10000 y_a = dbinom(x_a, 10000, 0.01) data = data.frame(x_a=x_a, area=append(rep(0, 119), seq(from=120, to=10000, by=1)), y_a=y_a) options(repr.plot.width=7, repr.plot.height=3) ggplot(data = data)+ labs(x="Number of successes", y="Probability") + xlim(50, 150) + geom_point(aes(x=x_a, y=y_a)) + geom_area(aes(x=area, y=y_a), colour="green", fill="green") |

We are now ready to quantify to what degree our null-hypothesis is true or false according to the numbers we collected in our experiment.
Type I and Type II errors
It is well known that statisticians do not have the same talent in the art of giving names as computer scientists do. This is well proved by the definition of Type I and Type II errors which are equivalent to the Machine learning definitions of False positive and False negative.
A Type I error is the probability of rejecting the null-hypothesis when the null-hypothesis is true. In our example this happens when we conclude there is an effect in our AB test variant, while in reality there is none.
A Type II error is the probability of failing to reject the null-hypothesis when the null-hypothesis is false. In our example this happens when we conclude the AB test variant has no effect, while in reality it actually did.
In the previous section we quantified the probability of Type I error, which is equivalent to the p-value returned by the binom.test function. To quantify the Type II error we need to know for what $pvalue = \alpha$ we are willing to reject the null-hypothesis. It is common practice to use $\alpha = 0.05$ so I’ll just go with that.
Now, what is the critical number of conversions such that we reject the null-hypothesis at $\alpha = 0.05$? This is called the percentile 14 and it is simply the $x_{\alpha}$ such that:
$P(X <= x_{\alpha}) = 1 – \alpha$
which can also be computed easily in R with the following:
|
1 2 3 |
alpha = 0.05 qbinom(1 - alpha, 10000, 0.01) # => 117 |
Now we know that starting from $117 + 1$ observations we will reject the null-hypothesis.
To compute the Type II error we need to assume that the null-hypothesis is false ($p_b = 0.012$) and quantify how likely it is to measure a value of $117$ or less since this is exactly what will lead us to a mistake!
$P(X_b <= 117) = P(X_b = 0) + P(X_b = 1) … + P(X_b = 117)$
which is equivalent to:
|
1 2 |
pbinom(117, 10000, 0.012) # => 0.414733285324603 |
which means that we have a ~= 40% chance to conclude our experiment did not have any effect, while in reality there was some.
That’s seems harsh to me. What can we do? Apply the first law of the modern age of statistics which is, get more data. Assuming we can double our data and get $20.000$ visitors instead of $10000$ and that we measure the same proportions, our Type II error will go down drammatically:
|
1 2 3 4 5 |
qbinom(0.95, 20000, 0.01) # critical value at which we reject the null-hypothesis # => 223 pbinom(223, 20000, 0.012) # type II error # => 0.141565461885161 |
now we have ~= 14% chance of concluding our experiment did not have any effect. We can even go one step further and see for every possible observation count what’s the expected Type II error by simply brute forcing the computation as follows:
|
1 2 3 4 5 6 7 8 9 |
v = c(); n = 1000:50000 for(i in n) { critical = qbinom(0.95, i, 0.01) t2_error = pbinom(critical, i, 0.012) v = append(v, t2_error) } options(repr.plot.width=7, repr.plot.height=3) qplot(n, v, xlab="P(type II error)", ylab="# Observations") |
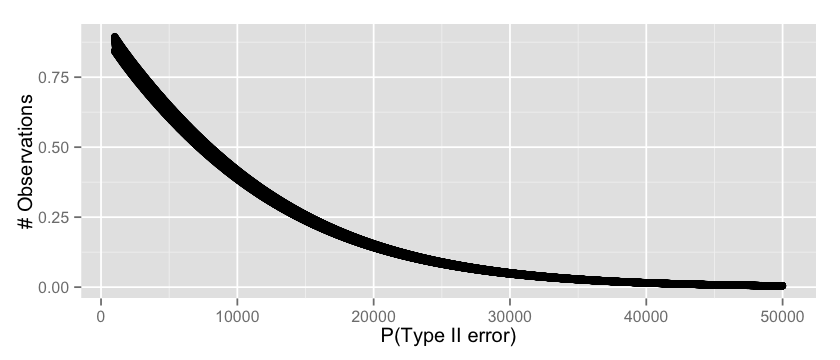
which seems a fair result, starting from $30.000$ visitors we can safely assume that our probability or Type II error will be low.
The analysis as I just presented it is flawed by a fundamental assumption. To estimate the Type I error we assumed that $p_b$ is exactly $0.012$ while to estimate the Type II error we assumed that $p_a$ is exactly $0.01$. We know from the CLT that this is not exactly true and the distributions of those values span across a certain range (see here). So let’s see what happens if I take several points across these distributions, for example the 1%, 25%, 50%, 75%, 99% percentiles and check what happens to our hypothesis testing errors.
For Type II errors I first collect the possible values of $p_a$ for my parametric analysis:
|
1 2 3 4 5 6 7 8 9 |
mean = 0.01 sigma = sqrt((mean * 0.99)/10000) p_a_values = c( qnorm(0.01, mean = mean, sd = sigma), qnorm(0.25, mean = mean, sd = sigma), qnorm(0.50, mean = mean, sd = sigma), qnorm(0.75, mean = mean, sd = sigma), qnorm(0.99, mean = mean, sd = sigma)) p_a_values |
and then I estimate the error exactly like I did previously:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# parametric Type II count = 50000; start = 1000 data = data.frame(x= numeric(0), error= numeric(0), parametric_mean = character(0)) p_a_values = factor(p_a_values) for(p_a in p_a_values) { n = start:(start+count) x = rep(0, count); error = rep(0, count); parametric_mean = rep('0', count); for(i in n) { p_a_numeric = as.numeric(as.character(p_a)) critical = qbinom(0.95, i, p_a_numeric) t2_error = pbinom(critical, i, 0.012) index = i - start + 1 x[index] = i error[index] = t2_error parametric_mean[index] = p_a } data = rbind(data, data.frame(x = x, error = error, parametric_mean=parametric_mean)) } options(repr.plot.width=7, repr.plot.height=3) ggplot(data=data, aes(x=x, y=error, color=parametric_mean, group=parametric_mean)) + geom_line() |
which produces the following:
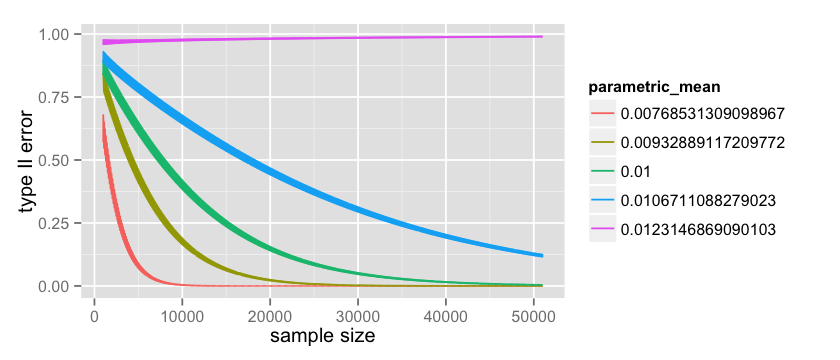
where the green line is the same as the one plotted here. It is quite interesting to observe the pink line at $p_a = 0.0123$. This is the worst case scenario for us since we picked a value that is greater than $p_b = 0.012$ and because of that our Type II error actually increases with the number of observations! However it is also worth mentioning that this value is very unlikely because the more data I collect the more the uncertainty around the values of $p_a$ decrease. You may also notice that the lines in the graph are quite thick, and this is because discrete tests like the binomial one 15 have quite large oscillations 16.
The same type of parametric analysis can be performed on the Type I error. Previously we saw how to compute it with the binom.test() function, but we can do the computation manually as follows when $p_a=0.01$ and $p_b=0.012$:
|
1 |
pbinom(119, 10000, 0.01, lower.tail=FALSE) |
where $119$ is the value starting from which we fail to reject the null-hypothesis. The parametric analysis is a generalisation of this code like we did for the Type II error:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# parametric Type I count = 50000 start = 1000 data = data.frame(x= numeric(0), error= numeric(0), parametric_mean = character(0)) p_b_values = factor(p_b_values) for(p_b in p_b_values) { n = start:(start+count) x = rep(0, count); error = rep(0, count); parametric_mean = rep('0', count); for(i in n) { p_b_numeric = as.numeric(as.character(p_b)) expected_b = i * p_b_numeric t1_error = pbinom(expected_b - 1, i, 0.01, lower.tail=FALSE) index = i - start + 1 x[index] = i error[index] = t1_error parametric_mean[index] = p_b } data = rbind(data, data.frame(x = x, error = error, parametric_mean=parametric_mean)) } options(repr.plot.width=7, repr.plot.height=3) ggplot(data=data, aes(x=x, y=error, color=parametric_mean, group=parametric_mean)) + geom_line() |
which plots the following:
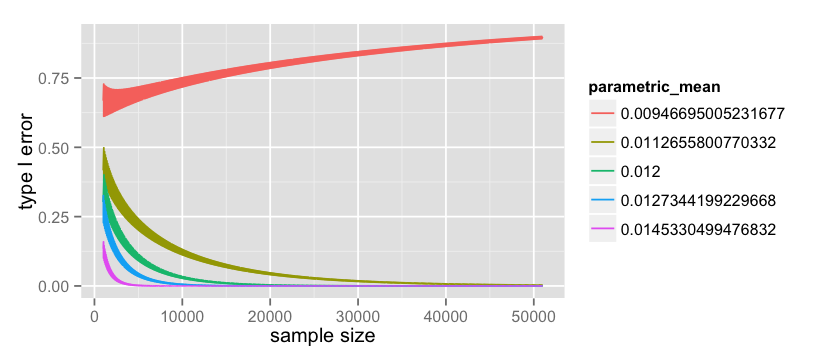
as in the Type II error we notice that for $p_b = 0.009$ the Type I error actually increase with the amount of data but this value become more and more unlikely as the data grows.
It also very interesting to notice how the value of the two type of errors goes down at a completely different rate. Overall, with this design, we are more likely to stick with the “button colour makes no difference” conclusion. When the reality is that button colour makes no difference, the tests will stick to reality most of the times (Type I error goes down quickly). When the reality is that button colour does make a difference, the test does take the risk of saying there is actually no difference between the two (Type II error goes down slowly).
Estimate the sample size
Before wrapping up let’s make a step back and position ourself back in time before we started the experiment. How we can estimate for how long we should run our experiment in order to be confident that our results are statistically significant? To answer this question you simply need to use the same tools we just saw, from a different perspective.
First, you need to make an estimate around your current baseline conversion. If you use google analytics it should be straightforward to know what is the conversion of your checkout page with the green button.
Second, you need to make a guess on what type of effect size you are willing to detect (minimum detectable effect size). In our example we would have chosen an effect size of 20%. In various disciplines effect sizes have been standardised to make different experiments comparable. Most famous effect size measure is Cohen’s d 17 18.
Third, you need to assert what risk you are willing to take on the Type I error, or equivalently, what $\alpha$ level you are willing to choose for your p-value. This is the value you will refer to at the end of the experiment to make your conclusion.
Finally, you need to assert what risk you are willing to take on the Type II error, or equivalently, how likely you are willing to say your orange button did not perfomed better when in reality there was an effect (i.e. orange button is better). This is equivalent to the power, where you assert how likely you are going to be correct when you conclude that the orange button is better, when it is actually real.
Mathematically speaking computing the required sample size seems to be a difficult problem in general and I would like to point you to the footnotes for a deeper discussion 19 20 21. Here I will show the approach taken from the Engineering statistics handbook 22.
First, we are look at the statistics:
$\delta = |p_a – p_b|$
and we would like to compute the sample size n such that:
(1) P(reject H0 | H0 is true) = $\alpha$
(2) P(reject H0 | H0 is false) = power = $1 – \beta$
Now, you have to use some faith and intuition. What is the smallest value of $\delta$, say $\delta_{min}$, that we care about? Our minimum detectable effect size! You can imagine $\delta_{min}$ is a function of both (1) and (2). The smallest value in (1) for which we start rejecting is:
$z_{1-\alpha} * \sqrt{\frac{p_a * (1-p_a)}{N}}$
while the smallest value in (2) for which we start rejecting is:
$z_{1-\beta} * \sqrt{\frac{p_b * (1-p_b)}{N}}$
where $power = 1 – \beta$ putting it all together we have:
$\delta_{min} = z_{1-\alpha} * \sqrt{\frac{p_a * (1-p_a)}{N}} +z_{1-\beta} * \sqrt{\frac{p_b * (1-p_b)}{N}}$
Take the N out of this equation and you get:
$N = (\frac{ z_{1-\alpha} * \sqrt{p_a * (1-p_a)} + z_{1-\beta} * \sqrt{p_b * (1-p_b)}}{\delta_{min}})^2$
So, using our example we state that: (i) our baseline conversion for the green button is 1% or $p_a = 0.01$; (ii) our estimate of effect size is 20% which leads to the orange button converting at 1.2% or $p_b = 0.012$; (iii) we accept a Type I error probability of 5% or $\alpha = 0.05$; (iv) we want a Power of 80% to make sure we detect the effect when it is there. This is translated in R as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
p_a = 0.01 p_b = 0.012 alpha = 0.05 beta = 0.2 delta = abs(p_a - p_b) t_alpha = qnorm(1 - alpha) t_beta = qnorm(1 - beta) sd1 = sqrt(p_a * (1-p_a)) sd2 = sqrt(p_b * (1-p_b)) n = ((t_alpha * sd1 + t_beta * sd2) / abs(p_a - p_b))^2 # => ~= 16294 |
which seems to be consistent with the simulations we did previously. On the other hand it is 30% lower than the one reported by a fairly famous online tool 23 24. If you know why please let me know in the comments.
Wrapping up
In this blog post we took a simple conversion table and we did a step by step statistical analysis of our results. Our experiment is designed like an extraction with replacement from a jar which is modelled with a binomial distribution.
We concluded that given the observed data the checkout page with the orange button is 20% more likely ((0.012 - 0.01) / 0.01) to convert than the one with the green button. If the green button is equivalent to the orange button (no effect), we came to the wrong conclusion with a probability of 2.76% (P(type I error), also called p-value). If the orange button is better than the green button, we came to the right conclusion with a probability of 60% (1 – P(type II error), also called the power). In this same scenario (orange button is better) if we double the number of visitors in our experiment our probability of being correct (power) will go up to 86%. Finally, we reviewed how to estimate the required sample size for our experiment in advance with a handy formula.
It is worth mentioning that in practice you rarely use a binomial test but I belive the simplicity of the distribution makes it adequate for this type of presentation. A better resource on choosing the right test can be found in the references 25.
If you enjoyed this blog post you can also follow me on twitter. Let me know your comments!
References
- Wikipedia page on A/B testing
- Extraction with replacement
- Binomial distribution
- Probability mass function
- 3 times standard deviation rule of thumb
- Central Limit Theorem
- Sampling Distributions
- The Central Limit Theorem around 1935
- Neyman and Pearson, Biometrika, 1928
- Wald, The Annals of Mathematical Statistics, 1939
- Lehmann and Romano, Springer Texts in Statistics, 2005
- One-tailed vs two-tailed tests
- p-value on wikipedia
- Percentile on Wikipedia
- Binomial test on Wikipedia
- Binomial test error oscillations on CrossValidated
- Thresholds for interpreting effect sizes
- Using Effect Size—or Why the P Value Is Not Enough
- Sample size determination for hypothesis testing of means
- Statistical Methods for Rates and Proportions, Third Edition
- Sample Size Calculation For
Comparing Proportions, Wiley Encyclopedia of Clinical Trials - Engineering statistics handbook – sample sizes required
- Evan Awesome AB Tools
- Evan Miller source code for sample size
- An Overview: choosing the correct statistical test
Excellent article!
Excellent article! A very thorough approach to performing a true A/B test.
Glad you enjoyed it! Thank you
This is great and astonishing that so many statisticians and scientists completely overlook effect size and power. What are your thoughts on a Bayesian approach that actually calculates a posterior? We have powerful computers now that can explicitly compute these probabilities.
Hi Barry, thank you for your comment.
In the Bayesian approach I think the main advantage is that the results are much easier to interpret compared to the hypothesis testing framework. In terms of the quantitative result it should be equivalent on the long run. Writing an article on the bayesian approach is definitely on my todo list, so I’ll get into the details 🙂
Thank you so much for such thorough post. I have a question regarding the ‘Estimate the sample size’ past. It says that the minimum value of Delta that we starts rejecting null hypothesis is z_(1-alpha)/sqrt(p_a(1-p_a)/N). Should it be z_(1-alpha)/sqrt(p_a(1-p_a)/N + p_b*(1-p_b)/N) as var(p_a-p_b) = Var(p_a) + Var(p_b)?
Hello Thu, glad you enjoyed!
Actually, the value of Delta such that we start rejecting the null hypothesis is
\delta_{min} = z_{1-\alpha} * \sqrt{\frac{p_a * (1-p_a)}{N}} +z_{1-\beta} * \sqrt{\frac{p_b * (1-p_b)}{N}}
so the third formula in that paragraph. This reference might also be useful:
https://www.itl.nist.gov/div898/handbook/prc/section2/prc242.htm
Let me know, have a nice day!
Alfredo
Hello,
Thanks a lot for this article!
one question: do you know how to come from your minimum size estimator to the one you have in: https://gist.github.com/mottalrd/7ddfd45d14bc7433dec2
I think I already know how. Writing Pb in terms of Pa>> Pb=Pa+delta, right?
Hi Andrea, I am glad it was useful!
It has been a while since I wrote this so I’d rather double check before saying something wrong!
It seems to me you got it right, but let me know if you still have doubts and I ll give it a check!
Have a nice day,
Alfredo
Hello, I think I know why your sample size computation is lower than the one from Evan Miller, there is one part missing in your code vis-a-vis his, it is: ” if (p > 0.5) {p = 1.0 – p}”, that would explain it no? But how do we explain that he considers this to be true?
Thank you Karim! It has been a long time for me since I wrote this so I am probably not equipped to reload it all in my brain to check if true or not, but I am sure this might help the next person who is pondering about this!
Really, thank you, you are the 1st author that made me understand intuitively how sample size is calculated! One question I have, many tools and authors do prefer to use pooled variance for this calculation, you do and Evan Miller chose not to do this… By using pooled variance (for A/B testing) we end us with slightly higher sample sizes, maybe it’s more “robust” what do you think?
Hi Karim, I might be wrong but intuitively it make sense that the sample size is higher because pooled variance assumes the two populations have the same variance so you need more data to disambiguate between them. I found this explanation to be useful; https://www.reddit.com/r/AskStatistics/comments/8rt10w/pooled_vs_unpooled_first_year_uni_stats/